Removing noise from Kepler, K2, and TESS light curves using Cotrending Basis Vectors (CBVCorrector)#
Cotrending Basis Vectors (CBVs) are generated in the PDC component of the Kepler/K2/TESS pipeline and are used to remove systematic trends in light curves. They are built from the most common systematic trends observed in each PDC Unit of Work (Quarter for Kepler, Campaign for K2 and Sector for TESS). Each Kepler and K2 module output and each TESS CCD has its own set of CBVs. You can read an introduction to the CBVs in Demystifying Kepler Data or to greater detail in the Kepler Data Processing Handbook. The same basic method to generate CBVs is used for all three missions.
This tutorial provides examples of how to utilize the various CBVs to clean lightcurves of common trends experienced by all targets. The technique exploits two goodness metrics that characterize the performance of the fit. CBVCorrector inherits the RegressionCorrector class in LightKurve. It is recommend to first read the tutorial on obtaining the CBVs before reading this tutorial.
Cotrending Basis Vector Types#
There are three basic types of CBVs:
Single-Scale contains all systematic trends combined in a single set of basis vectors.
Multi-Scale contains systematic trends in specific wavelet-based band passes. There are usually three sets of multi-scale basis vectors in three bands.
Spike contains only short impulsive spike systematics.
There are two different correction methods in PDC: Single-Scale and Multi-Scale. Single-Scale performs the correction in a single bandpass. Multi-Scale performs the correction in three separate wavelet-based bandpasses. Both corrections are performed in PDC but we can only export a single PDC light curve for each target. So, PDC must choose which of the two to export on a per-target basis. Generally speaking, single-scale performs better at preserving longer period signals. But at periods close to transiting planet durations multi-scale performs better at preserving signals. PDC therefore mostly chooses multi-scale for use within the planet finding pipeline and for the archive. You can find in the light curve FITS header which PDC method was chosen (keyword “PDCMETHD”). Additionally, a seperate correction is alway performed to remove short impulsive systematic spikes.
For an individual’s research needs, the mission supplied PDC lightcurves might not be ideal and so the CBVs are provided to the user to perform their own correction. All three CBV types are provided at MAST for TESS, however only Single-Scale is provided at MAST for Kepler and K2. Also for Kepler and K2, Cotrending Basis Vectors are supplied for only the 30-minute target cadence.
Obtaining the CBVs#
One can directly obtain the CBVs with load_tess_cbvs and load_kepler_cbvs, either from MAST by default or from a local directory cbv_dir. However when generating a CBVCorrector object the appropriate CBVs are automatically downloaded from MAST and aligned to the lightcurve. Let’s generate this object for a particularily interesting TESS variable
target. We first download the SAP lightcurve.
[1]:
%matplotlib inline
from lightkurve import search_lightcurve
import numpy as np
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
lc = search_lightcurve('TIC 99180739', author='SPOC', sector=10).download(flux_column='sap_flux')
Next, we create a CBVCorrector object. This will download the CBVs appropriate for this target and store them in the CBVCorrector object. In the case of TESS, this means the CBVs associated with the CCD this target is on and for Sector 10.
[2]:
from lightkurve.correctors import CBVCorrector
cbvCorrector = CBVCorrector(lc)
Let’s look at the CBVs downloaded.
[3]:
cbvCorrector.cbvs
[3]:
[TESS CBVs, Sector.Camera.CCD : 10.1.1, CBVType : SingleScale, nCBVS : 16,
TESS CBVs, Sector.Camera.CCD : 10.1.1, CBVType.Band: MultiScale.1, nCBVs : 8,
TESS CBVs, Sector.Camera.CCD : 10.1.1, CBVType.Band: MultiScale.2, nCBVs : 8,
TESS CBVs, Sector.Camera.CCD : 10.1.1, CBVType.Band: MultiScale.3, nCBVs : 8,
TESS CBVs, Sector.Camera.CCD : 10.1.1, CBVType : Spike, nCBVS : 6]
We see that there are a total of 5 sets of CBVs, all associated with TESS Sector 10, Camera 1 and CCD 1. The number of CBVs per type is also given. Let’s plot the Single-Scale CBVs, which contain all systematics combined.
[4]:
cbvCorrector.cbvs[0].plot();
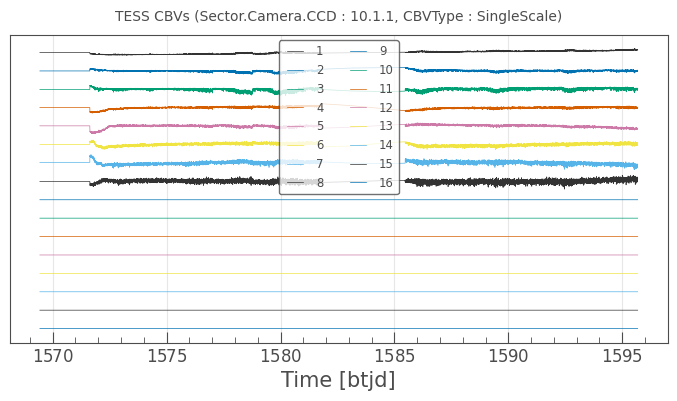
The first several CBVs contain most of the systematics. The latter CBVs pose a greater risk of injecting more noise than helping. The default behavior in CBVCorrector is to use the first 8 CBVs.
Assessing Over- and Under-Fitting with the Goodness Metrics#
Two very common issues when fitting a model to a data set it over-fitting and under-fitting.
Over-fitting occurs when the model has too many degrees of freedom and fits the data at all costs, instead of just modelling the physical process it is attempting to model. This can exhibit itself in different ways, depending on the system and application. In the case of fitting systematic trend basis vectors to a time series, over-fitting can result in the basis vectors removing intrinsic signals in the times series instead of just the systematics. It can also result in introduced broad-band noise. This can be particularily prominant in an unconstrained least-squares fit. A least-squares fit only cares about minimizing it’s loss function, which is the Root Mean Square error. In the course of minimizing the RMS, narrow-band power representing the systematic trends are exchanged for broad-band noise intrinsic in the basis vectors. This results in the overall RMS decreasing but the noise in the time series increasing, resulting in the obscuration of the signals under interest. A very common method to inhibit over-fitting is to introduce a regularization term in the loss function. This constrains the fit and effectively reduces the degrees of freedom.
Under-fitting occurs when the model has too few degrees of freedom and fails to adequately model the physical process it is attempting to model. In the case of fitting systematic trend basis vectors to a time series, under-fitting can result in residual systematics. Under-fitting can either be the result of the basis vectors not adequately representing the systematics or, placing too great of a restriction on the model during fitting. The regularization technique used to inhibit over-fitting can therefore result in under-fitting. The ideal fit will balance the counter-acting phenomena of over- and under-fitting. To this end, a method can be developed to measure the degree to which these two phenomena occur.
PDC has two Goodness Metrics to assess over- and under-fitting:
Over-fitting metric: Measures the introduced noise in the light curve after the correction. It does so by measuring the broad-band power spectrum via a Lomb-Scargle Periodogram both before and after the correction. If power has increased after the correction then this is an indication the CBV fit has over-fitted and introduced noise. The metric treats all frequencies equally when measuring power increase; from one frequency separation to the Nyquist frequency. This metric is callibrated such that a metric value of 0.5 means the introduced noise due to over-fitting is at the same power level as the uncertainties in the light curve.
Under-fitting metric: Measures the mean residual target to target Pearson correlation between the target under study and a selection of neighboring targets. This metric will find and download a selection of neighboring SPOC SAP targets in RA and Decl. until a minimum number is found. The metric is callibrated such that a value of 0.95 means the residual correlations in the target is equivalent to chance correlations of White Gaussian Noise.
The Goodness Metrics are not perfect! They are an estimate of over- and under-fitting and are to be used as a guideline along other other metrics to assess the quality of your light curve.
The Goodness Metrics are part of the lightkurve.correctors.metrics module and can be computed directly with calls to overfit_metric_lombscargle and underfit_metric_neighbors. The ‘CBVCorrector’ has convenience wrappers for the two metrics and so they do not need to be called directly, as we will show below.
Example Correction with CBVCorrector to Inhibit Over-Fitting#
There are four correction methods within CBVCorrector:
correct: Performs a numerical correction using the LightKurve RegressionCorrector.correct method while optimizing the L2-Norm regularization penalty term using the goodness metrics as the Loss Function.
correct_gaussian_prior: Performs an analytical correction using the LightKurve RegressionCorrector.correct method while setting the L2-Norm (Ridge Regression) regularization penalty term as the Gaussian prior.
correct_elasticnet: Performs the correction using Scikit-Learn’s ElasticNet, which combines both an L1- and L2-Norm regularization.
correct_regressioncorrector: Performs the standard RegressionCorrector.correct correction. RegressionCorrector is the superclass to CBVCorrector and this is a “passthrough” method to access the superclass
correctmethod.
If you are unfamilar with L1-Norm (LASSO) and L2-Norm (Ridge Regression) regularization then there are severel, excellent, introductions. You can read how a L2-norm relates to a Gaussian prior in a linear design matrix in this reference.
The default method is correct and generally speaking, one can use just this method to obtain a good fit. The other methods are for advanced usage.
We’ll start with correct_gaussian_prior in order to introduce the concepts. Doing so will allow us to force a very weak regularization term (alpha=1e-4) as an illustration.
[5]:
# Select which CBVs to use in the correction
cbv_type = ['SingleScale', 'Spike']
# Select which CBV indices to use
# Use the first 8 SingleScale and all Spike CBVS
cbv_indices = [np.arange(1,9), 'ALL']
# Perform the correction
cbvCorrector.correct_gaussian_prior(cbv_type=cbv_type, cbv_indices=cbv_indices, alpha=1e-4)
cbvCorrector.diagnose();
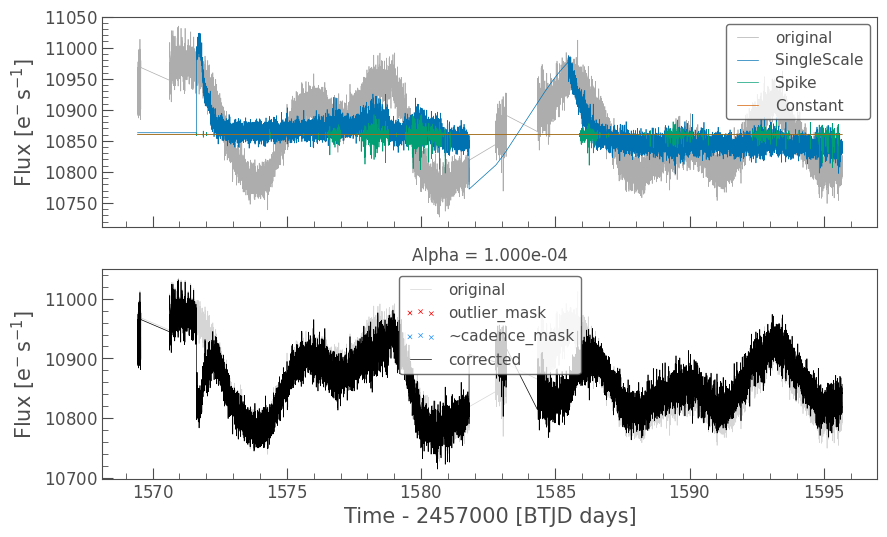
First note that CBVCorrector always fits a constant term in the model, but the constant is never subtracted in the resultant corrected flux. The median flux value of the light curve is always preserved.
At first sight, this looks like a good correction. Both the Single-Scale and Spike basis vectors are being utilized to fit out as much of the signal as possible. The corrected light curve is indeed flatter. But this was essentially an unrestricted least-squares correction and we may have over-fitted. The very strong lips right at the beginning of each orbit is probably a chance correlation between the star’s inherent stellar variability and the thermal settling systematic that is common in Kepler and TESS lightcurves. Let’s look at the CBVCorrector goodness metrics to determine if this is the case.
[ ]:
# Note: this cell will be slow to run
print('Over fitting Metric: {}'.format(cbvCorrector.over_fitting_metric()))
print('Under fitting Metric: {}'.format(cbvCorrector.under_fitting_metric()))
Over fitting Metric: 0.7123518503044495
The first time you run the under-fitting goodness metric it will download the SPOC SAP light curves of targets in the neighborhood around the target under study in order to estimate the residual systematics (they are stored in the CBVCorrector object for subsequent computations). A goodness metric of 0.8 or above is generally considered good. In this case, it looks like we over-fitted (over-fitting metric = 0.71). Even though the corrected light curve looks better, our metric is telling us we probably injected signals into our lightcurve and we should not trust this really nice looking curve. Perhaps we can do better if we regularize the fit.
Using the Goodness Metrics to Optimize the Fit#
We will start by performing a scan of the over- and under-fit goodness metrics as a function of the L2-Norm regularization term, alpha.
[8]:
cbvCorrector.goodness_metric_scan_plot(cbv_type=cbv_type, cbv_indices=cbv_indices);
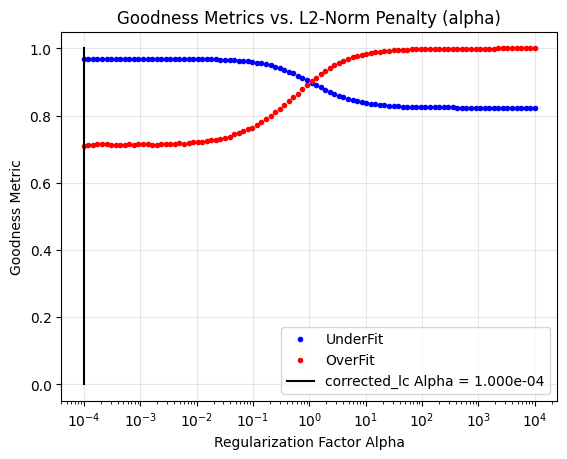
This scan also plots the last used alpha parameter as a vertical black line (alpha=1e-4 in our case). We are clearly not optimizing this fit for both over- and under-fitting. Let’s use the correct numerical optimizer to try to optimize the fit.
[9]:
cbvCorrector.correct(cbv_type=cbv_type, cbv_indices=cbv_indices);
cbvCorrector.diagnose();
cbvCorrector.goodness_metric_scan_plot(cbv_type=cbv_type, cbv_indices=cbv_indices);
Optimized Over-fitting metric: 0.9996566787964412
Optimized Under-fitting metric: 0.8235711805082385
Optimized Alpha: 9.640e+03
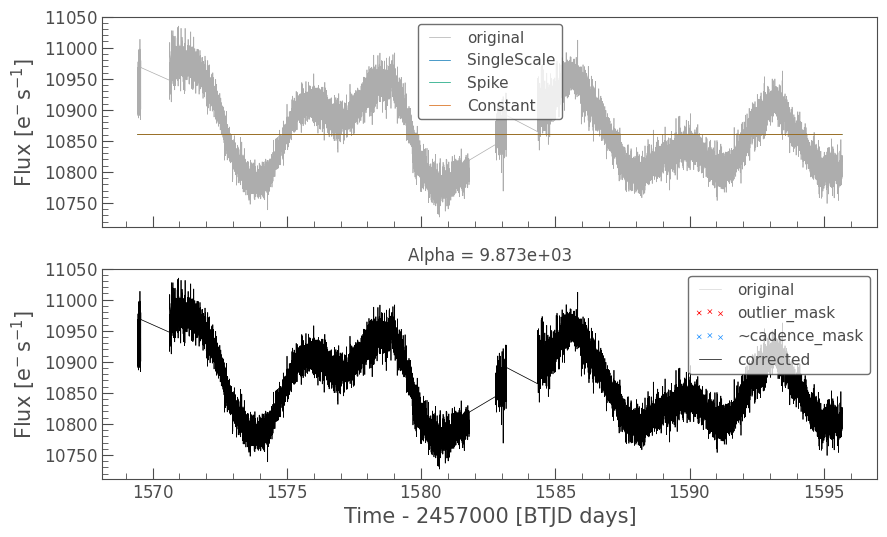
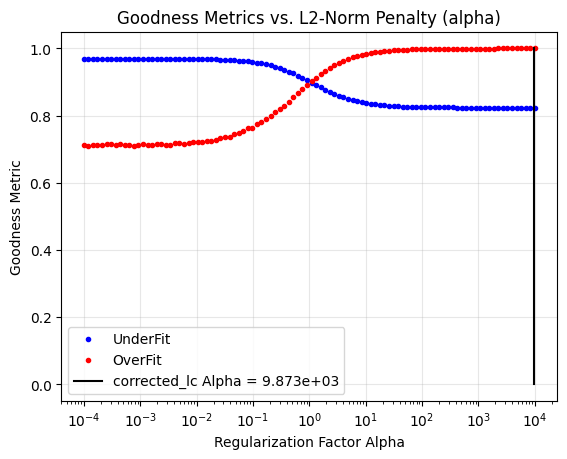
Much better! We see the thermal settling systematic is still being removed, but the stellar variabity is better preserved. Note that the optimizer did not set the alpha parameter at exactly the red and blue curve intersection point. The default target goodness scores is 0.8 or above, which is fulfilled at alpha=1.45e-1. If we want to optimize the fit even more, by perhaps ensuring we are not over-fitting at all, then we can adjust the target over and under scores to emphasize which metric we are more interested in. Below we more greatly emphasize improving the over-fitting metric by setting the target to 0.9.
[10]:
cbvCorrector.correct(cbv_type=cbv_type,
cbv_indices=cbv_indices,
target_over_score=0.9,
target_under_score=0.5)
cbvCorrector.diagnose();
cbvCorrector.goodness_metric_scan_plot(cbv_type=cbv_type, cbv_indices=cbv_indices);
Optimized Over-fitting metric: 0.9996528005184675
Optimized Under-fitting metric: 0.8235709911208746
Optimized Alpha: 9.443e+03
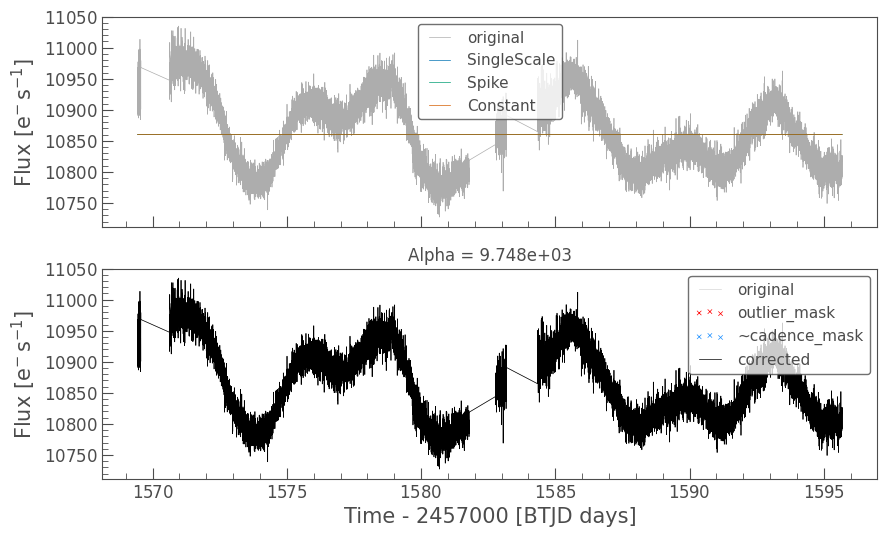
We are now perhaps biasing too far towards under-fitting, but depending on your research interests, this might be best.
No Single Best Answer Example#
Let’s now look at another example, this time where there is no clear single best answer. Again, we will use the Single-Scale and Spike basis vectors for the correction and begin with low regularization.
[11]:
lc = search_lightcurve('TIC 38574307', author='SPOC', sector=2).download(flux_column='sap_flux')
cbvCorrector = CBVCorrector(lc)
cbv_type = ['SingleScale', 'Spike']
cbv_indices = [np.arange(1,9), 'ALL']
cbvCorrector.correct_gaussian_prior(cbv_type=cbv_type, cbv_indices=cbv_indices, alpha=1e-4)
cbvCorrector.diagnose();
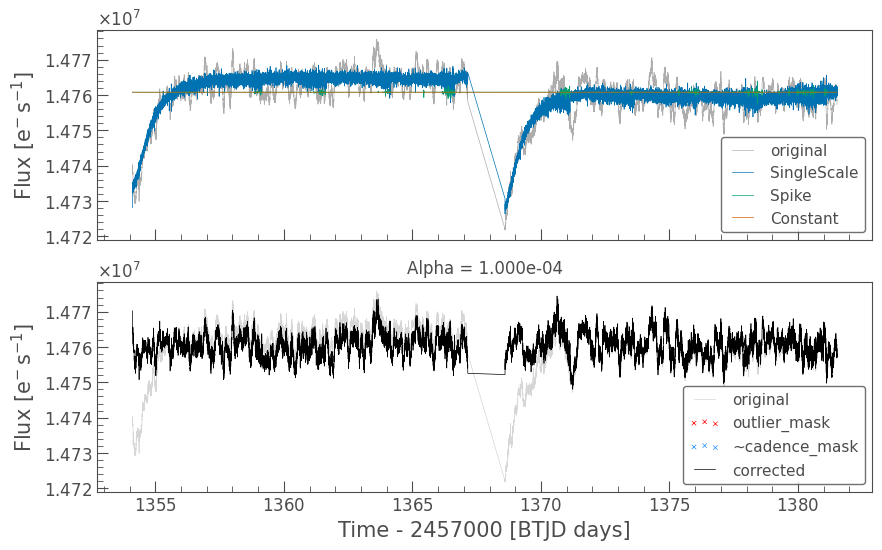
At first sight, this looks good. The long term trends have been removed and the periodic noisy bits have been removed with the spike basis vectors. But did we really do a good job?
[12]:
print('Over fitting Metric: {}'.format(cbvCorrector.over_fitting_metric()))
print('Under fitting Metric: {}'.format(cbvCorrector.under_fitting_metric()))
cbvCorrector.goodness_metric_scan_plot(cbv_type=cbv_type, cbv_indices=cbv_indices);
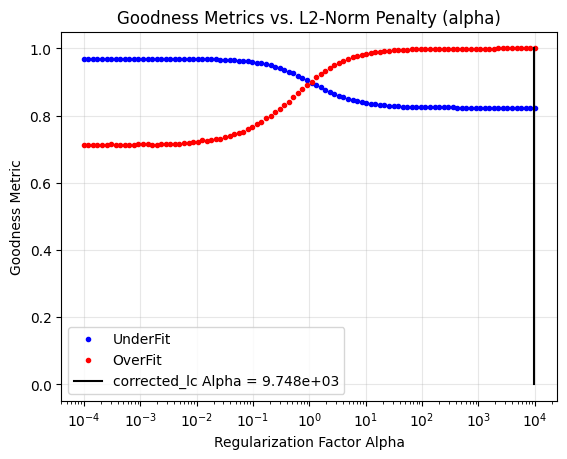
Over fitting Metric: 0.2617079411722498
---------------------------------------------------------------------------
TimeoutError Traceback (most recent call last)
Cell In[12], line 2
1 print('Over fitting Metric: {}'.format(cbvCorrector.over_fitting_metric()))
----> 2 print('Under fitting Metric: {}'.format(cbvCorrector.under_fitting_metric()))
3 cbvCorrector.goodness_metric_scan_plot(cbv_type=cbv_type, cbv_indices=cbv_indices);
File ~/tessgi/dev/lightkurve/lkmain-docs/lightkurve/src/lightkurve/correctors/cbvcorrector.py:623, in CBVCorrector.under_fitting_metric(self, radius, min_targets, max_targets)
621 while (continue_searching):
622 try:
--> 623 metric = underfit_metric_neighbors (corrected_lc,
624 dynamic_search_radius, min_targets, max_targets,
625 interpolate, extrapolate)
626 except MinTargetsError:
627 # Too few targets found, try increasing search radius
628 if (dynamic_search_radius > max_search_radius):
629 # Hit the edge of the CCD, we have to give up
File ~/tessgi/dev/lightkurve/lkmain-docs/lightkurve/src/lightkurve/correctors/metrics.py:184, in underfit_metric_neighbors(corrected_lc, radius, min_targets, max_targets, interpolate, extrapolate, quality_bitmask)
181 corrected_lc_flux = corrected_lc.flux.value
183 # Download and pre-process neighboring light curves
--> 184 lc_neighborhood, lc_neighborhood_flux = _download_and_preprocess_neighbors(
185 corrected_lc=corrected_lc,
186 radius=radius,
187 min_targets=min_targets,
188 max_targets=max_targets,
189 interpolate=interpolate,
190 extrapolate=extrapolate,
191 flux_column="sap_flux",
192 quality_bitmask=quality_bitmask,
193 )
195 # Create fluxMatrix. The last entry is the target under study
196 # Check that all neighboring targets have similar shape
197 if not np.all([len(lc_neighborhood_flux[0]) == len(l) for l in lc_neighborhood_flux]):
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/memoization/caching/plain_cache.py:42, in get_caching_wrapper.<locals>.wrapper(*args, **kwargs)
40 with lock:
41 misses += 1
---> 42 result = user_function(*args, **kwargs)
43 cache[key] = values_toolkit.make_cache_value(result, ttl)
44 key_argument_map[key] = (args, kwargs)
File ~/tessgi/dev/lightkurve/lkmain-docs/lightkurve/src/lightkurve/correctors/metrics.py:327, in _download_and_preprocess_neighbors(corrected_lc, radius, min_targets, max_targets, interpolate, extrapolate, author, flux_column, quality_bitmask)
324 if extrapolate and (extrapolate != interpolate):
325 raise Exception('interpolate must be True if extrapolate is True')
--> 327 search = corrected_lc.search_neighbors(
328 limit=max_targets, radius=radius, author=author,
329 )
330 if len(search) < min_targets:
331 raise MinTargetsError(
332 f"Unable to find at least {min_targets} neighbors within {radius} arcseconds radius."
333 )
File ~/tessgi/dev/lightkurve/lkmain-docs/lightkurve/src/lightkurve/lightcurve.py:3098, in LightCurve.search_neighbors(self, limit, radius, **search_criteria)
3093 # Note: we increase `limit` by one below to account for the fact that the
3094 # current light curve will be returned by the search operation
3095 log.info(
3096 f"Started searching for up to {limit} neighbors within {radius} arcseconds."
3097 )
-> 3098 result = search_lightcurve(
3099 f"{self.ra} {self.dec}", radius=radius, limit=limit + 1, **search_criteria
3100 )
3102 # Filter by distance > 0 to avoid returning the current light curve
3103 result = result[result.distance > 0]
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/memoization/caching/plain_cache.py:42, in get_caching_wrapper.<locals>.wrapper(*args, **kwargs)
40 with lock:
41 misses += 1
---> 42 result = user_function(*args, **kwargs)
43 cache[key] = values_toolkit.make_cache_value(result, ttl)
44 key_argument_map[key] = (args, kwargs)
File ~/tessgi/dev/lightkurve/lkmain-docs/lightkurve/src/lightkurve/search.py:833, in search_lightcurve(target, radius, exptime, cadence, mission, author, quarter, month, campaign, sector, limit)
733 """Search the `MAST data archive <https://archive.stsci.edu>`_ for light curves.
734
735 This function fetches a data table that lists the Light Curve Files
(...)
830 >>> search_lightcurve('Kepler-10', radius=100, quarter=4, exptime=1800).download_all() # doctest: +SKIP
831 """
832 try:
--> 833 return _search_products(
834 target,
835 radius=radius,
836 filetype="Lightcurve",
837 exptime=exptime or cadence,
838 mission=mission,
839 provenance_name=author,
840 quarter=quarter,
841 month=month,
842 campaign=campaign,
843 sector=sector,
844 limit=limit,
845 )
846 except SearchError as exc:
847 log.error(exc)
File ~/tessgi/dev/lightkurve/lkmain-docs/lightkurve/src/lightkurve/search.py:997, in _search_products(target, radius, filetype, mission, provenance_name, exptime, quarter, month, campaign, sector, limit, **extra_query_criteria)
995 if filetype.lower() == "ffi" and radius is None:
996 radius = 0.0001 * u.arcsec
--> 997 observations = _query_mast(
998 target,
999 radius=radius,
1000 project=mission,
1001 provenance_name=provenance_name,
1002 exptime=exptime,
1003 sequence_number=campaign or sector,
1004 **extra_query_criteria,
1005 )
1006 log.debug(
1007 "MAST found {} observations. "
1008 "Now querying MAST for the corresponding data products."
1009 "".format(len(observations))
1010 )
1011 if len(observations) == 0:
File ~/tessgi/dev/lightkurve/lkmain-docs/lightkurve/src/lightkurve/search.py:1225, in _query_mast(target, radius, project, provenance_name, exptime, sequence_number, **extra_query_criteria)
1223 warnings.filterwarnings("ignore", category=NoResultsWarning)
1224 warnings.filterwarnings("ignore", message="t_exptime is continuous")
-> 1225 obs = Observations.query_criteria(objectname=target, **query_criteria)
1226 obs.sort("distance")
1227 # We use `exptime` as an alias for `t_exptime`
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/astroquery/utils/class_or_instance.py:25, in class_or_instance.__get__.<locals>.f(*args, **kwds)
23 def f(*args, **kwds):
24 if obj is not None:
---> 25 return self.fn(obj, *args, **kwds)
26 else:
27 return self.fn(cls, *args, **kwds)
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/astroquery/utils/process_asyncs.py:28, in async_to_sync.<locals>.create_method.<locals>.newmethod(self, *args, **kwargs)
24 @class_or_instance
25 def newmethod(self, *args, **kwargs):
26 verbose = kwargs.pop('verbose', False)
---> 28 response = getattr(self, async_method_name)(*args, **kwargs)
29 if kwargs.get('get_query_payload') or kwargs.get('field_help'):
30 return response
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/astroquery/utils/class_or_instance.py:25, in class_or_instance.__get__.<locals>.f(*args, **kwds)
23 def f(*args, **kwds):
24 if obj is not None:
---> 25 return self.fn(obj, *args, **kwds)
26 else:
27 return self.fn(cls, *args, **kwds)
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/astroquery/mast/observations.py:339, in ObservationsClass.query_criteria_async(self, pagesize, page, resolver, **criteria)
335 service = self._caom_filtered
336 params = {"columns": "*",
337 "filters": mashup_filters}
--> 339 return self._portal_api_connection.service_request_async(service, params, pagesize=pagesize, page=page)
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/astroquery/utils/class_or_instance.py:25, in class_or_instance.__get__.<locals>.f(*args, **kwds)
23 def f(*args, **kwds):
24 if obj is not None:
---> 25 return self.fn(obj, *args, **kwds)
26 else:
27 return self.fn(cls, *args, **kwds)
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/astroquery/mast/discovery_portal.py:364, in PortalAPI.service_request_async(self, service, params, pagesize, page, **kwargs)
361 mashup_request[prop] = value
363 req_string = _prepare_service_request_string(mashup_request)
--> 364 response = self._request("POST", self.MAST_REQUEST_URL, data=req_string, headers=headers,
365 retrieve_all=retrieve_all)
367 return response
File ~/miniforge3/envs/lk-dev/lib/python3.11/site-packages/astroquery/mast/discovery_portal.py:188, in PortalAPI._request(self, method, url, params, data, headers, files, stream, auth, retrieve_all)
183 response = super(PortalAPI, self)._request(method, url, params=params, data=data,
184 headers=headers, files=files, cache=False,
185 stream=stream, auth=auth)
187 if (time.time() - start_time) >= self.TIMEOUT:
--> 188 raise TimeoutError("Timeout limit of {} exceeded.".format(self.TIMEOUT))
190 # Raising error based on HTTP status if necessary
191 response.raise_for_status()
TimeoutError: Timeout limit of 600 exceeded.
Hmm… The over-fitting goodness metric says we are severely over-fitting. Not only that, there appears to not be an Alpha parameter that brings both goodness metrics above 0.8. And yet, the fit looks really good. What’s going on here? Let’s zoom in on the correction.
[ ]:
pltAxis = cbvCorrector.diagnose()
pltAxis[0].set_xlim(1360.5, 1361.1)
pltAxis[0].set_ylim(1.4755e7, 1.477e7);
pltAxis[1].set_xlim(1360.5, 1361.1)
pltAxis[1].set_ylim(1.475e7, 1.477e7);
We see in the top plot that the SingleScale correction has comperable noise to the original light curve. This means the correction is injecting high frequency noise at comperable amplitude to the original signal. We have indeed over-fitted! The goodness metrics perform a broad-band analysis of over- and under-fitting. Even though our eyes did not see the high frequency noise injection, the goodness metrics did. So, what should be done? It depends on what you are trying to investigate. If you are only looking at the low frequency signals in the data then perhaps you don’t care about the high frequency noise injection. If you really do care about the high frequency signals then you should increase the Alpha parameter, or set the target goodness scores as we do below (target_over_score=0.8, target_under_score=0.5).
[ ]:
# Optimize the fit but overemphasize the importance of not over-fitting.
cbvCorrector.correct(cbv_type=cbv_type,
cbv_indices=cbv_indices,
target_over_score=0.8,
target_under_score=0.5)
cbvCorrector.diagnose()
cbvCorrector.goodness_metric_scan_plot(cbv_type=cbv_type, cbv_indices=cbv_indices);
[ ]:
# Again, zoom in to see the detail
pltAxis = cbvCorrector.diagnose()
pltAxis[0].set_xlim(1360.5, 1361.1)
pltAxis[0].set_ylim(1.4755e7, 1.477e7);
pltAxis[1].set_xlim(1360.5, 1361.1)
pltAxis[1].set_ylim(1.475e7, 1.477e7);
We see now that the high frequency noise injection is small compared to the original amplitudes in the lightkurve. We barely removed any of the systematics and are now under-fitting, but that might be the best we can do if we want to ensure low noise injection.
…Or Can We Still Do Better?#
Perhaps we are using the incorrect CBVs for this target. Below is a tuned multi-step fit where we first fit the multi-scale Band 2 CBVs then the Spike CBVs. The multi-scale band 2 CBVs contain intermediate frequency systematic signals. They should not inject high frequency noise. We also utilize the correct_elasticnet corrector, which allows us to add in a L1-Norm term (Lasso Regularization). L1-Norm helps snap some basis vector fit coefficients to zero and can result in a more stable, less
noisy fit. The result is a much better compromise between over- and under-fitting. The spikes are not well removed but increasing the weight on the Spike CBV removal results in over-fitting. We can also try the multi-scale band 3 CBVs, which contain high frequency systematics, but the over-fitting metric indicates using them results in even greater over-fitting. The resultant is now much better than what we achieved above but more tuning and optimization could possibly get us even closer to an
ideal fit.
[ ]:
# Fit to the Multi-Scale Band 2 CBVs with ElasticNet to add in a L1-Norm (Lasso) term
cbvCorrector.correct_elasticnet(cbv_type=['MultiScale.2'], cbv_indices=[np.arange(1,9)], alpha=1.0e-7, l1_ratio=0.5)
ax = cbvCorrector.diagnose()
ax[0].set_title('Result of First Correction to MultiScale.2 CBVs');
# Set the corrected LC as the initial LC in a new CBVCorrector object before moving to the next correction.
# You could instead just reassign to the first cbvCorrector object, if you do not wish to save the original.
cbvCorrectorIter2 = cbvCorrector.copy()
cbvCorrectorIter2.lc = cbvCorrectorIter2.corrected_lc.copy()
# Fit to the Spike Basis Vectors, using an L1-Norm term.
cbvCorrectorIter2.correct_elasticnet(cbv_type=['Spike'], cbv_indices=['ALL'], alpha=2.0e-5, l1_ratio=0.7)
ax = cbvCorrectorIter2.diagnose()
ax[0].set_title('Result of Second Correction to Spike CBVs');
[ ]:
# Compute the final goodness metrics compared to the original lightcurve.
# This requires us to copy the original light curve into cbvCorrectorIter2.lc so that the goodness metrics compares the corrected_lc to the proper initial light curve.
cbvCorrectorIter2.lc = cbvCorrector.lc.copy()
print('Over-fitting Metric: {}'.format(cbvCorrectorIter2.over_fitting_metric()))
print('Under-fitting Metric: {}'.format(cbvCorrectorIter2.under_fitting_metric()))
# Plot the final correction
_, ax = plt.subplots(1, figsize=(10, 6))
cbvCorrectorIter2.lc.plot(ax=ax, normalize=False, alpha=0.2, label='Original')
cbvCorrectorIter2.corrected_lc[~cbvCorrectorIter2.cadence_mask].scatter(
normalize=False, c='r', marker='x',
s=10, label='Outliers', ax=ax)
cbvCorrectorIter2.corrected_lc.plot(normalize=False, label='Corrected', ax=ax, c='k')
ax.set_title('Comparison between original and final corrected lightcurve');
So, which CBVs are best to use? There is no one single answer, but generally speaking, the Multi-Scale Basis vectors are more versatile. The trade-off is there are also more of them, which means more degrees of freedom in your fit. More degrees of freedom can result in more over-fitting without proper regularization. It is recommened the user tries different combinations of CBVs and use objective metrics to decide which fit is the best for their particular needs.
Using the Goodness Metrics and CBVCorrector with other Design Matrices#
The Goodness Metrics and CBVCorrector can also be used in conjunction with other external design matrices. Let’s work on a famous planet example to show how the CBVCorrector can be utilized to imporove the generated light curve. We will begin by using search_tesscut to extract an FFI light curve for HAT-P 11 and then create a DesignMatrix using the background pixels.
[ ]:
# HAT-P 11b
from lightkurve import search_tesscut
from lightkurve.correctors import DesignMatrix
search_result = search_tesscut('HAT-P-11', sector=14)
tpf = search_result.download(cutout_size=20)
# Create a simple thresholded aperture mask
aper = tpf.create_threshold_mask(threshold=15, reference_pixel='center')
# Generate a simple aperture photometry light curve
raw_lc = tpf.to_lightcurve(aperture_mask=aper)
# Create a design matrix using PCA components from the cutout background
dm = DesignMatrix(tpf.flux[:, ~aper], name='pixel regressors').pca(5).append_constant()
The DesignMatrix dm now contains the common trends in the background pixels in the data. We will first try to fit the pixel-based design matrix using an unrestricted least-squares fit (I.e. a very weak regularization by setting alpha to a small number). We tell CBVCorrector to only use the external design matrix with ext_dm=. When we generate the
CBVCorrector object the CBVs will be downloaded, but the CBVs are for 2-minute cadence and not the 30-minute FFIs. We therefore use the interpolate_cbvs=True option to tell the CBVCorrector to interpolate the CBVs to the light curve cadence.
[ ]:
# Generate the CBVCorrector object and interpolate the downloaded CBVs to the light curve cadence
cbvcorrector = CBVCorrector(raw_lc, interpolate_cbvs=True)
# Perform an unrestricted least-squares fit using only the pixel-derived design matrix.
cbvcorrector.correct_gaussian_prior(cbv_type=None, cbv_indices=None, ext_dm=dm, alpha=1e-4)
cbvcorrector.diagnose()
print('Over-fitting metric: {}'.format(cbvcorrector.over_fitting_metric()))
print('CDPP: {}'.format(cbvcorrector.corrected_lc.estimate_cdpp()))
corrected_lc_just_pixel_dm = cbvcorrector.corrected_lc
The least-squares fit did remove the background flux trend and at first sight the resultant might look good, but the over-fitting goodness metric is 0.08. That’s not very good! It looks like we are dramatically over-fitting. We can see this in the bottom plot where the corrected curve has more high-frequency noise than the original. Let’s now add in the multi-scale basis vectors and see if we can do better. Note that we are joint fitting the CBVs and the external pixel-derived design matrix.
[ ]:
cbv_type = ['MultiScale.1', 'MultiScale.2', 'MultiScale.3','Spike']
cbv_indices = [np.arange(1,9), np.arange(1,9), np.arange(1,9), 'ALL']
cbvcorrector.correct_gaussian_prior(cbv_type=cbv_type, cbv_indices=cbv_indices, ext_dm=dm, alpha=1e-4)
cbvcorrector.diagnose()
print('Over-fitting metric: {}'.format(cbvcorrector.over_fitting_metric()))
print('CDPP: {}'.format(cbvcorrector.corrected_lc.estimate_cdpp()))
corrected_lc_joint_fit = cbvcorrector.corrected_lc
That looks a lot better! Could we do a bit better by adding in a regularization term? Let’s do a goodness metric scan.
[ ]:
cbvcorrector.goodness_metric_scan_plot(cbv_type=cbv_type, cbv_indices=cbv_indices, ext_dm=dm);
There are a couple observations to make here.
First, the under-fitting metric has a very good score throughout the regularization scan. This is because the under-fitting metric compares the corrected light curve to neighboring targets in RA and Decl. that are archived as 2-minute SAP-flux targets. The SAP flux already has the background removed so the neighoring targets do not contain the very large background trends. The under-fitting metric is therefore not very helpful. In the next run we will disable the under-fitting metric in the optimization (by setting target_under_score=-1).
We see the over-fitting metric is not a simple function of the regularization factor alpha. This can happen due to the interaction of the various basis vectors during fitting when regularization is applied. We see a minima (most over-fitting) at about alpha=1e-1. Once alpha moves above this value we begin to over-constrain the fit which results in gradually less removal of systematics. The under-fitting metric should be an indicator that we are going too far constraining the fit, and indeed, we do see the under-fitting metric degrades slightly beginning at alpha=1e-1.
We will now try to optimize the fit and account for these two issues by 1) setting the bounds on the alpha parameter (alpha_bounds=[1e-6, 1e-2]) and 2) disregarding the under-fitting metric (target_under_score=-1).
[ ]:
# Optimize the fit but ignore the under-fitting metric and set bounds on the alpha parameter.
cbvcorrector.correct(cbv_type=cbv_type, cbv_indices=cbv_indices, ext_dm=dm, alpha_bounds=[1e-6, 1e-2], target_over_score=0.8, target_under_score=-1)
cbvcorrector.diagnose();
print('CDPP: {}'.format(cbvcorrector.corrected_lc.estimate_cdpp()))
This is looking like a pretty good light curve. However, the CDPP increased a little as we optimized the over-fitting metric. Which correction to use may depend on your application. Since we are interested in the transiting planet, we will choose the corrected light curve with the lowest CDPP. Below we compare the light curve between just using the pixel-derived design matrix to also adding in the CBVs as a joint, regularized fit.
[ ]:
_, ax = plt.subplots(3, figsize=(10, 6))
cbvcorrector.lc.plot(ax=ax[0], normalize=False, label='Uncorrected LC', c='k')
corrected_lc_just_pixel_dm.plot(normalize=False, label='Pixel-Level Corrected; CDPP={0:.1f}'.format(corrected_lc_just_pixel_dm.estimate_cdpp()), ax=ax[1], c='m')
corrected_lc_joint_fit.plot(normalize=False, label='Joint Fit Corrected; CDPP={0:.1f}'.format(corrected_lc_joint_fit.estimate_cdpp()), ax=ax[2], c='b')
ax[0].set_title('Comparison Between original and final corrected lightcurve');
The superiority of the bottom curve is blatantly obvious. We can clearly see HAT-P 11b on it’s 4.9 day period orbit. Our over-fitting metric settled at about 0.35 indicating we might still be over-fitting and should keep that in mind. However the low CDPP indicates the over-fitting is probably not over transit time-scales.
Some final comments on CBVCorrector#
Application to Kepler vs K2 vs TESS#
CBVCorrector works equally across Kepler, K2 and TESS. However the Multi-Scale and Spike basis vectors are only available for TESS1. For K2, the PLDCorrector and SFFCorrector classes might work better than
CBVCorrector.
If you want to just get the CBVs but not generate a CBVCorrector object then use the functions load_kepler_cbvs and load_tess_cbvs within the cbvcorrector module as explained here.
1 Unfortunately, the Multi-Scale and Spike CBVs are not archived at MAST for Kepler/K2.
Applicability of the Over- and Under-fitting Goodness Metrics#
The under-fitting metric computes the correlation between the corrected light curve and a selection of neighboring SPOC SAP light curves. If the light curve you are trying to correct was not generated by the SPOC pipeline (I.e. not a SAP light curve), then the neighboring SAP light curves might not contain the same instrumental systematics and the under-fitting metric might not properly measure when under-fitting is occuring.
The over-fitting metric examines the periodogram of the light curve before and after the correction and is therefore indifferent to how the light curve was generated. It simply looks to see if noise was injected into the light curve. The over-fitting metric is therefore much more generally applicable.
The Goodness Metrics are part of the lightkurve.correctors.metrics module and can be computed directly with calls to overfit_metric_lombscargle and underfit_metric_neighbors. A savvy expert user can use these and other quality metrics to generate their own Loss Function for optimizing a fit.
Aligning versus Interpolating CBVs#
By default, all loaded CBVS in CBVCorrector are “aligned” to the light curve cadence numbers (CBVCorrector.lc.cadenceno). This means only cadence numbers that exist in both the CBVs and the light curve will have values in the returned CBVs. All cadence numbers that exist in the light curve but not in the CBVs will have NaNs returned for the CBVs on those cadences and the Gap Indicator set to True. Any cadences in the CBVs not in the light curve will be removed from the CBVs.
If the light curve cadences do not overlap well with the CBVs then you can set interpolate_cbvs=True when generating the CBVCorrector object. Doing so will generate interpolated CBV values for all cadences in the light curve. If the light curve has cadences past either end of the cadences in the CBVs then one must extrapolate. A second argument, extrapolate_cbvs, can be used to also extrapolate the CBV values to the light curve cadences. If extrapolate_cbvs=False then the
exterior values are set to NaNs, which will probably result is a very poor fit.
Warning: The safest method is to align. This will not generate any new values for the CBVs. Interpolation can be potentially dangerous. Interpolation uses Piecewise Cubic Hermite Interpolating Polynomial (PCHIP), which can be more stable than a simple spline, but no interpolation method works in all situations. Extrapolation is even more dangerious, which is why an extra parameter must be set if one desires to extrapolate. Be sure to manually examine the extrapolated CBVs before use!
Joint Fitting#
By including the ext_dm= parameter in the correct_* methods we allow for joint fitting between the CBVs and other design matrices. Generally speaking, if fitting a collection of different models to a system, joint fitting is ideal. For example, if performing transit analysis one could add in a transit model to the joint fit to get the best transit recovery. The fit coefficient to the transit model is stored in the CBVCorrector object after fitting and can be recovered.
Hyperparameter Optimization#
Any model fitting should include a hyperparameter optimization step. The correct_optimizer is essentially a 1-dimensional optimizer and is very fast. More advanced hypterparameter optimization can be performed by tuning the alpha and l1_ratio parameters in correct_elasticnet plus the number and type of CBVs, along with an external design matrix. The optimization Loss Function can use a combination of the under_fitting_metric, over_fitting_metric and lc.estimate_cdpp
methods. Writing such an optimzer is left as an exercise to the reader and to be tuned to the reader’s particular application.
More Generalized Design Matrix Priors#
The main CBVCorrector.correct* methods utilize a similar prior for all design matrix vectors as is typically used in L1-Norm and L2-Norm regularization. However you can perform fine tuning to the correction using more sophisticated priors. After performing a fit with one of the CBVCorrector.correct* methods,
CBVCorrector.design_matrix_collection will have the priors set. One can then manually adjust the priors and use CBVCorrector.correct_regressioncorrector to perform the standard RegressionCorrector.correct correction. An illustration is below:
[ ]:
# 1) Perform an initial optimization with a L2-Norm regularization
# cbvCorrector.correct(cbv_type=cbv_type, cbv_indices=cbv_indices);
# 2) Examine the quality of the resultant lightcurve in cbvcorrector.corrected_lc
# Determine how to adjust the priors and make changes to the design matrix
# cbvCorrector.design_matrix_collection[i].prior_sigma[j] = # ... adjust the priors
# 3) Call the superclass correct method with the adjusted design_matrix_collection
# cbvCorrector.correct_regressioncorrector(cbvCorrector.design_matrix_collection, **kwargs)
The cbvCorrector.corrected_lc will now be the result of the fit using whatever cbvCorrector.design_matrix_collection you had just provided.
NaNs, Units and Normalization#
NaNs are removed from the light curve when used to generate the CBVCorrector object and is stored in CBVCorrector.lc.
The CBVCorrector performs its corrections in absolute flux units (typically electrons per second). The returned corrected light curve corrected_lc is also in absolute units and the median flux of the light curve is preserved.
[ ]:
print('LC unit: {}'.format(cbvCorrector.lc.flux.unit))
print('Corrected LC unit: {}'.format(cbvCorrector.corrected_lc.flux.unit))
The goodness metrics are computed using median normalized units in order to properly calibrate the metric to be between 0.0 and 1.0 for all light curves. The normalization is as follows:
[ ]:
normalized_lc = cbvCorrector.lc.normalize()
normalized_lc -= 1.0
print('Normalized Light curve units: {} (i.e astropy.units.dimensionless_unscaled)'.format(normalized_lc.flux.unit))
[ ]: